用python开发软件时,由于操作系统中可能存在多个不同的python版本,并且在不同版本、不同目录下安装了各种各样的python包,导致开发环境的不一致,也会带来发布软件时运行环境的问题。通过python的包管理器pip和环境管理器virtualenv,可以很容易解决这些问题。
0%
规则引擎中常用的模式匹配算法
规则引擎的核心是Pattern Matcher(模式匹配器)。不管是正向推理还是反向推理,首先要解决一个模式匹配的问题。
前面提到,规则引擎的核心是Pattern Matcher(模式匹配器)。不管是正向推理还是反向推理,首先要解决一个模式匹配的问题。
对于规则的模式匹配,可以定义为: 一个规则是一组模式的集合。如果事实/假设的状态符合该规则的所有模式,则称为该规则是可满足的。 模式匹配的任务就是将事实/假设的状态与规则库中的规则一一匹配,找到所有可满足的规则。
什么是模式匹配
对于模式匹配我们都应该不陌生,我们经常使用的正则表达式就是一种模式匹配。
- 正则表达式是一种“模式(pattern)”
- 编程语言提供的“正则表达式引擎”就是Pattern Matcher。比如python中的re模块
- 首先输入“知识”:re.compile(r’string’)
- 然后就可以让其匹配(match)事实(字符串)
- 最后通过正则表达式引擎可以得到匹配后的结果
对于规则匹配,通常定义如下:
- 条件部分,也称为LHS(left-hand side)
- 事实部分,也称为RHS(right-hand side)
假设系统中有N条规则,平均每个规则的条件部分有P个模式,在某个时点有M个事实需要处理。则规则匹配要做的事情就是: 对每一个规则r,判断当前的事实o是否满足LHS(r)=True,如果满足,则将规则r的实例r(o),即规则+满足该规则的事实,加到冲突集中等待处理。 通常采取如下过程:
- 从N条规则中取出一条r;
- 从M个事实中取出P个事实的一个组合c;
- 用c测试LHS(r),如果LHS(r(c))=True,将RHS(r(c))加入队列中;
- 如果M个事实还存在其他的组合c,goto 3;
- 取出下一条规则r,goto 2;
实际的问题可能更复杂,在规则的执行过程中可能会改变RHS的数据,从而使得已经匹配的规则实例失效或者产生新的满足规则的匹配,形成一种“动态”的匹配链。
上面的处理由于涉及到组合,过程很复杂。有必要通过特定的算法优化匹配的效率。目前常见的模式匹配算法包括Rete、Treat、Leaps,HAL,Matchbox等。
Rete算法
Rete算法是目前使用最广泛的规则匹配算法,由Charles L. Forgy博士在1979年发明。Rete算法是一种快速的Forward-Chaining推理算法,其匹配速度与规则的数量无关。 Rete的高效率主要来自两个重要的假设:
时间冗余性
假设facts在推理过程中的变化是缓慢的, 即在每个执行周期中,只有少数的facts发生变化,因此影响到的规则也只占很小的比例。所以可以只考虑每个执行周期中已经匹配的facts.
结构相似性
假设许多规则常常包含类似的模式和模式组。
Rete算法的基本思想是保存过去匹配过程中留下的全部信息,以空间代价来换取执行效率 。对每一个模式 ,附加一个匹配元素表来记录WorkingMemory中所有能与之匹配的元素。当一个新元素加入到WorkingMemory时, 找出所有能与之匹配的模式, 并将该元素加入到匹配元素表中; 当一个无素从WorkingMemory中删除时,同样找出所有与该元素匹配的模式,并将元素从匹配元素表中删除。 Rete算法接受对工作存储器的修改操作描述 ,产生一个修改冲突集的动作 。
Rete算法的步骤如下:
- 将初始数据(fact)输入Working Memory。
- 使用Pattern Matcher比较规则(rule)和数据(fact)。
- 如果执行规则存在冲突(conflict),即同时激活了多个规则,将冲突的规则放入冲突集合。
- 解决冲突,将激活的规则按顺序放入Agenda。
- 使用规则引擎执行Agenda中的规则。重复步骤2至5,直到执行完毕所有Agenda中的规则。
Tread算法
在 Rete算法中 ,同一规则连接结点上的寄存器保留了大量的冗余结果。实际上, 寄存器中大部分信息已经体现在冲突集的规则实例中。因此 ,如果在部分匹配过程中直接使用冲突集来限制模式之间的变量约束,不仅可以减少寄存器的数量 ,而且能够加快匹配处理效率 。这一思想称为 冲突集支撑策略 。
考虑增删事实对匹配过程的影响,当向工作存储器增加一个事实时 ,冲突集中已有的规则实例仍然保留,只是将与该事实匹配的规则实例加入到冲突集中; 当从工作存储器删去一个事实时,不可能有新的规则实例产生, 只是将 包含该事实的规则实例从冲突集中删去。
基于冲突集支撑策略和上述观察, Treat算法放弃了Rete算法中利用寄存器保存模式之间变量约束中间结果的思想,对于每一个模式 ,除保留原有 a寄存器的外 ,增加两个新链来记录与该模式匹配的增删事实,一个叫做增链 (addlist),另一个叫做删链 (deletelist)。当修改描述的操作符为 “+”时,临时执行部分连接任务;当修改描述的操作符为 “一”时,直接删去冲突集中包含该事实的规则实例。
Treat算法的步骤如下:
- 行动 :根据点火规则的 RHS,生成修改描述表 CHANGES;
- 模式匹配:置每一模式的删链和增链为空,对 CHANGES的每一个修改描述 ,执行模式匹配。对于与修改描述中的事实匹配成功的模式,若修改描述的操作符为 “+”, 将该事实加入这一模式的增链;若修改描述的操作符为 “一”,将该事实加入这一模式的 删链。
- 删去事实的处理:对于任一模式链中的每一个事实,找到冲突集中所有包含该事实 的规则实例,并将这一规则实例从冲突集中删去。相应地修改该模式的 a寄存器 。
- 新增事实的处理:对 于 每 一 模 式 ,若 其 增 链 非 空 ,则 将 增 链 中 的 所 有 事 实 加 入 该 模 式的a寄存器 ,并对与新增事实相关的每一条规则临时执行部分匹配,寻找该规则新的实 例。具体做法为:首先将第一个模式增链中的事实集合与后一模式的 a寄存器进行连接 , 再将部分连接结果与第三个模式的a寄存器进行连接 ,一直到所有模式均连接完成为止。 其中 ,a寄存器 的内容包括新增 事实。若连接结果非空 ,则将找到 的规则 实例插入到冲突 集中。
Leaps 算法
前向推理引擎,包括LEAPS,都包括了匹配-选择-执行(match-select-action)循环。即,确定可以匹配的规则,选择某个匹配的元 组,此元组相应的规则动作被执行。重复这一过程,直到某一状态(如没有更多的规则动作)。RETE和TREAT匹配算法速度慢的原因是,它们把满足规则条 件的元组都实例化。Leaps算法的最大的改进就是使用一种”lazy”的方法来评估条件(conditions),即仅当必要时才进行元组的实例化。这 一改进极大的减少了前向推理引擎的时空复杂度,极大提高了规则执行速度。
Leaps算法将所有的 asserted 的 facts ,按照其被 asserted 在 Working Memory 中的顺序( FIFO ),放在主堆栈中。它一个个的检查 facts ,通过迭代匹配 data type 的 facts 集合来找出每一个相关规则的匹配。当一个匹配的数据被发现时,系统记住此时的迭代位置以备待会的继续迭代,并且激发规则结果( consequence )。当结果( consequence )执行完成以后,系统就会继续处理处于主堆栈顶部的 fact 。如此反复。
Leaps算法的效率可以比Rete算法和Tread算法高几个数量级。
其他算法
对于HAL算法和Matchbox算法,使用的范围不是很广,这里不做过多的介绍。
CEP:鱼与熊掌可以兼得
简单的说,事件驱动模式包括三个参与者:事件产生者,事件分发器和事件处理器。
从事件驱动编程(Event-driven Programming)开始
如果你写过GUI程序,对事件处理一定不陌生。事实上,事件驱动编程已经成为一种设计模式。大多数的GUI库都会采用这一模式。
简单的说,事件驱动模式包括三个参与者:事件产生者,事件分发器和事件处理器。
- 事件产生者(Events Generator)
决定是否需要产生事件。比如,GUI上的每个组件都是一个事件产生者,可以根据用户操作产生鼠标事件或者键盘事件。
- 事件分发器(Events Dispatcher)
收集所有事件产生者发出的事件放入事件队列(Events Queue),
并根据事件的类型将事件分发给已经注册的事件处理器。事件分发器通常由GUI框架实现。
- 事件处理器(Events Handler)
根据接收到的事件进行处理,需要GUI框架的使用者自行编写。
事件驱动编程的核心价值在于:程序的执行流程不是预先定义好的,而是由程序的使用者决定的。这将极大增强程序的交互性。
就好像DVD与RPG游戏的区别:前者的剧情是设定好的,你只能进行开始、暂停、快进、回退等有限的交互;后者可以决定主角的行为从而影响故事的结局。
事件驱动业务(Event-driven Business)
代码的世界不可能是现实世界的完整镜像,但一定是对现实世界的某种抽象,这种抽象能够简化代码世界中对问题的分析和处理。
同时,这种抽象还可以反向映射到现实世界,为我们解决现实问题提供思路。
现代企业生存的外部环境处于剧烈的变化之中,“敏捷企业”已经成为生存之道,而事件驱动业务是敏捷企业的一个基本要求。
事件驱动业务(Event-driven Business),是在 连续
的业务过程中进行决策的一种业务管理方式,即根据不同时点上出现的一系列事件触发相关的任务,并调度可用的资源执行任务。
如果说事件驱动编程能够为软件带来更灵活的交互性和强大的功能,那么企业中的事件驱动业务能够大幅度提高业务的效率和灵活性。
事件驱动业务依托于比较成熟的信息化建设。各个业务应用系统在产生连续不断的数据流的同时,根据定义好的条件产生一些“业务事件”,按照策略对这些业务事件进行分析处理,触发新的业务事件或者业务流程,即实现了业务的事件驱动。
从上面的描述可以看出,事件驱动业务要求能够快速(毫秒级)、不间断的处理连续、海量的数据,具备灵活的规则或策略设置,从而具备迅速识别、捕获、响应实时业务数据的能力。
而传统的企业IT架构通常采用:
- 在业务应用系统中处理业务操作
- 遵循固定的业务流程(Business
Process)处理跨系统事务,并且这些流程很少变化 - 基于数据仓库进行海量数据的存储及事后分析
这种IT架构远远达不到事件驱动业务的要求。
事件驱动业务能够应用的业务领域很多,凡是需要快速处理连续性数据、需要能够灵活制定策略的业务,都可以采用事件驱动的业务模式。如证券行业常见的风险分析预警(事前及事中风控)、投资决策(程序化交易)、经纪人绩效计算等。
业务事件处理的几个层次
其实在传统的IT架构中,我们已经实现了业务事件的处理。比如在传统的业务应用系统中,我们通常将业务数据存储在数据库中,通过应用系统的操作界面由人工发现和处理业务事件。
这样的处理方式存在两个不足,一是速度慢,二是对于复杂的情况只靠人脑难以处理。于是有了两个技术方向:
- 消息队列(MQ)
对于速度慢的解决办法是用机器代替人工,为了在多个系统之间传递消息,发展出了消息队列(MQ)的技术 - 商业智能(BI)
为了应对复杂性,通过数据仓库将数据整合到一起,并用专门的工具在数据模型的基础上进行分析
但是上述两个方向是正交的:MQ不适合处理复杂性,而BI主要适应于对结构化的历史数据的分析,无法处理“现在”的情况。
CEP:鱼与熊掌可以兼得
CEP(Complex Event
Processing)的出现解决了上述两个方面的问题,在实时性和复杂性方面都得到了很好的解决。
处理数据流
不管是单独的应用系统,还是数据仓库,都是先将数据存储到数据库/数据仓库,然后再处理或查询。
而CEP与MQ类似的将数据看作是 数据流
。在连续数据的快速移动过程中进行分析处理。
这样的方式不需要很大的数据加载,完全可以在内存中进行,从而能够快速产生结果。

处理复杂性
业务事件可能很复杂,在各种不同的数据流中源源不断产生各种类型的事件。需要对这些业务事件进行复杂的计算,如过滤、关联、聚合等,同时还需要考虑这些也是事件出现的时间序列。
最终才能产生有意义的事件,或触发业务流程。同时,这些计算的规则可能还会经常变化。
这一类的问题通常通过基于规则的推理机(即规则引擎)来实现。

CEP的架构

综上所述,CEP在逻辑上应该包括:
事件发生器
通过应用系统、文件系统、数据库、互联网、人工、以及传感器产生事件事件处理器 模式的匹配、验证和改进,路由,转换以及编排
事件消费者
与事件发生器类似,也可以是应用系统、文件系统、数据库、互联网、人工界面等小结
CEP是一种比较新的企业架构(EA,Enterprise
Architure)组件。CEP将数据看做一种数据流,基于规则引擎对业务过程中持续产生的各种事件进行复杂的处理,能够实现对连续数据的快速分析处理。可以应用在多种业务场景,如风险分析、程序化交易等。
如果说BI实现了商业智能,那么CEP则实现了“持续智能(Continuous
Intelligence)“。
NoSQL数据库选型指引
从设计原则上,NoSQL不再强调ACID(酸),而是强调BASE(碱)。什么是NoSQL
NoSQL可以有两种解释:
- No SQL:“不使用SQL查询语言”。强调其轻量的特点
- Not Only SQL:”不仅仅是查询“。强调其高性能,分布式,大容量等传统关系数据库所不具备的特性
从设计原则上,NoSQL不再强调ACID(酸),而是强调BASE(碱)。
ACID是指:
- atomicity(原子性):一个事务中的所有操作,要么全部完成,要么全部不完成。如果中途发生错误需要回滚(Rollback)
- consistency(一致性):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。這表示寫入的資料必須完全符合所有的預設規則,這包含資料的精確度、串聯性以及後續数据库可以自發性地完成預定的工作。
- isolation(隔離性):当两个或者多个事务并发访问(此处访问指查询和修改的操作)数据库的同一数据时所表现出的相互关系。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)
- durability(持久性):在事务完成以后,该事务对数据库所作的更改便持久地保存在数据库之中,并且是完全的
BASE是指:
- Basically Available(基本可用)
- Soft-state(软状态/柔性事务)
- Eventually Consistent(最终一致性)
NoSQL与关系数据库的原则不同:NoSQL牺牲高一致性,换取获得可用性或可靠性。软状态意味着状态是异步的,在某些时段状态是不一致的;但最终一致保证数据早晚会一致。
NoSQL选型要素
存储结构
由于NoSQL的目的和原则的不同,NoSQL中的数据不是按照表存储。根据NoSQL存储结构的不同,可以分为:
- 文档存储
- 图存储
- key/value儲存
- 列存储
- 对象数据库
是否持久化
有的NoSQL是纯内存存储,不支持持久化
是否支持嵌入式
是否支持集群部署
操作接口的丰富程度
常见的NoSQL数据库
- 文档数据库
| 名称 | 持久化 | 部署方式 | 操作接口 | 备注 | |
| CouchDB | 分布式 | JavaScript MapReduce, RESTful JSON API | HTTP访问,内置了Web管理控制台 | ||
| JackRabbit | Java | ||||
| Lotus Notes | LotusScript, Java | ||||
| BaseX | XQuery, Java | ||||
| MongoDB | 服务,集群 | PHP,Python,Perl,Ruby,JavaScript,C++等 | JSON数据库,支持全文索引,自动分片,跨LAN或WAN扩展 |
- 图形数据库
| 名称 | 持久化 | 部署方式 | 操作接口 | 备注 |
| Neo4j | Java | |||
| DEX | Java , C# | |||
| AllegroGraph | SPARQL | |||
| FlockDB | Scala |
- key/value数据库
| 名称 | 持久化 | 部署方式 | 操作接口 | 备注 |
| BigTable | ||||
| memcached | ||||
| Redis | ||||
| Oracle Berkeley DB |
- 列数据库
| 名称 | 持久化 | 部署方式 | 操作接口 | 备注 |
| Cassandra | ||||
| HBase | ||||
| Hypertable |
- 对象数据库
| 名称 | 持久化 | 部署方式 | 操作接口 | 备注 |
| db4o | ||||
| iBoxDB | ||||
| JADE | ||||
| ZODB | ||||
| ObjectStore |
如何规划blog的分类和标签
使用知识地图的思想规划博客的标签(tags)和分类(categories)
一篇旧的博文,原文发表在博客园。
知识地图与知识管理
一篇旧的博文,原文发表在博客园。
QQ 餐厅与系统性能模型(续):如何评价系统的性能
作为QQ餐厅的客人,对餐厅效率的评价就是供餐“快”或者“慢”。但是对于餐厅的经营者,这样简单的考虑问题显然是不够的。
在《QQ餐厅与系统性能模型》 中提到了系统性能的很多指标,而客人感觉“快”或者“慢”仅仅对应其中的 响应时间 这一指标。本文讨论如何全面评价一个系统的性能”
QQ餐厅与系统性能模型
本文以QQ餐厅作为模型,讨论系统性能的主要指标。
统一web访问层方案
使用nginx和keepalived搭建统一的web访问层,并实现负载均衡、高可用、回话保持。这是为公司做的一个真实方案。
开发和部署JBoss FUSE中的路由(Route)
快速开始
因为Fuse的核心组成部分是ServiceMix,而ServiceMix的核心组成部分是Apache
Camel,所以“用Fuse开发路由”也就是“开发Camel路由”。
Camel提供了大量的开发工具
,其中camel-archetype-blueprint
是一个maven
archetype,
可以基于Blueprint,以依赖注入的方式配置CamelContext。下面快速创建一个demo:
1 | mvn archetype:generate \ |
会创建如下结构的一个工程:
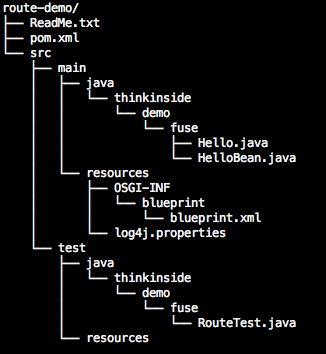
从 pom.xml
来看,这是一个使用maven-bundle-plugin构建的OSGibundle工程。
基于Blueprint装配Camel
Context
工程的`META-INF/blueprint/blueprint.xml’文件是一个Blueprint配置文件:
1 | <?xml version="1.0" encoding="UTF-8"?> |
该配置文件中,定义了一个id为 blueprintContext 的Camel
Context。这个Context中定义了一个路由:
- 入口为一个Timer类型的Endpoint
- 使用预定义的bean为Message设置body
- 记录日志
- 出口为一个Mock类型的Endpoint
如果使用FuseIDE,可以看到图形化的配置界面:

部署到ServiceMix
执行 mvn package 后,得到 route-demo-1.0.0-SNAPSHOT.jar
,这是一个OSGi bundle。可以将jar文件部署到
=$SERVICEMIXHOME/deploy/=
目录中。正常情况下,bundle的依赖关系被满足,该bundle会被自动启动。
从ServiceMix到Fuse
上述的过程也适用于JBoss Fuse。
但是Fuse对ServiceMix进行了再次封装,需要使用Fuse对应的版本。比如,=camel-archetype-blueprint=
的版本可能要使用 2.10.0.redhat-60024
这样的“Fuse版本号”,否则在部署到Fuse是可能会发生版本不匹配的问题。
Fuse提供了一个maven仓库,专门提供这种定制版本的组件,需要在maven中配置:
1 | <repository> |