规则引擎中,将知识表达为规则(rules),要分析的情况定义为事实(facts)。二者在内存中的存储分别称为Production Memory和Working Memory。在外围,还会有一个执行引擎(Execution Engine)。
与此对应,规则引擎API也分成三个部分。在Drools中,分别叫做Knowledge API,Fact API和Execution API。
规则引擎中,将知识表达为规则(rules),要分析的情况定义为事实(facts)。二者在内存中的存储分别称为Production Memory和Working Memory。在外围,还会有一个执行引擎(Execution Engine)。
与此对应,规则引擎API也分成三个部分。在Drools中,分别叫做Knowledge API,Fact API和Execution API。
股票行情数据具有如下特点:
数据量大
对于分析来说,至少需要5分钟数据。如果每天交易时间为4小时,每年250个交易日,则一支股票一年的行情数据量为60/54250= 12k。20年则为240k。如果是1分钟数据,则20年的数据量为240k*5 = 1.2M。
所以,如果用于分析,行情数据将是百万量级。如果记录3000只股票/指数的数据,数据量会非常大。
数据很少变化
由于都是历史数据,行情数据很少需要修改。主要的操作是查询和增加。
数据结构简单
主要考虑成交数据,是一种简单的一维结构。价格数据只在发生交易信号时有一定的参考意义,不需要保留所有的历史记录。
由于行情数据的这些特点,通常不适合使用关系数据库。传统上一般采用数据文件进行存储。
但是用数据文件需要自己处理写入锁,随机读写,序列化等问题,比较麻烦。于是NoSQL成了比较好的一种选择。
对于单机的分析软件,NoSQL选型要素为:
Berkeley DB是满足上述4点要求的比较好的一款产品。Berkeley DB分为BDB、BDB Java版和BDB XML版。其总体架构如下图:

BDB的三个版本的功能不完全相同。
我选择BDB Java版,不支持SQL API和XQuery API,可以使用底层的键/值API、Java 直接持久层 (DPL) API和Java 集合 API。三种API的应用场景如下:
在行情数据的持久化中,可以选用直接持久层(DPL)。直接持久层API 可以持久化以及还原相互关联的 Java 对象,但是比ORM更加简单高效。
可以从这里下载需要的jar包,也可以使用maven:
1 | <dependency> |
如果要使用最新版(目前的最新版是5.0.97),需要引入oracle的maven库:
1 | <repositories> |
Berkeley DB支持DDD(领域驱动设计)中的实体和值对象的持久化。
在BDB中,分别使用 @Entity 和 @Persistent 来声明实体和值对象。
声明了 @Persistent 的对象可以直接作为 @Entity 对象中的属性使用。
任何Java类一旦增加了持久化声明,其所有字段(任何作用域)都会被持久化。需要持久化的类需要缺省的无参数构造函数。
比如:
1 |
|
每个实体类(@Entity)可以定义一个主键(PrimaryKey)和多个次键(SecondaryKey),从而可以按照主键或次键进行索引。例如:
1 |
|
关联关系也是通过次键(SecondaryKey)声明的。需要同时指定多重性(relate)和关联到的实体(relatedEntity)。
relate可以是ONE_TO_ONE,ONE_TO_MANY,MANY_TO_ONE或MANY_TO_MANY(在com.sleepycat.persist.model.Relationship中定义)。
需要注意的是,次键的属性类型需要是relatedEntity指定的对端实体的主键类型,而不能直接使用对端实体。
如果relate是ONE_TO_MANY或MANY_TO_MANY,可以使用集合类型。比如(不属于股票行情数据模型,而是BDB官方例子):
1 |
|
类似于DAO,BDB中通常将对实体的访问封装到Accessor中。例如:
EntityStore
获取索引
CRUD
访问关联对象
通过索引可以得到关联的对象,无论是单个关联对象还是集合。
1 | EntityCursor<Person> employees = dao.personByEmployerIds.subIndex(gizmoInc.id).entities(); |
通过 EntityJoin 类可以进行等值连 接(equality join)操作。
比如,以下代码查询所有Bob的孩子中为gizmo公司工作的 员工:
1 | EntityJoin<String,Person> join = new EntityJoin(dao.personBySsn); |
1 | Transaction txn = env.beginTransaction(null, null); dao.employerById.put(txn, gizmoInc); dao.employerById.put(txn, gadgetInc); |
对于增加实体或值对象的属性,改变属性类型等变化,一般不需要对BDB进行额外的处理,而是会自动适应。
对于一些特殊的、无法自动适应的变化,比如重命名字段或优化单个的类(如:使用通用类型,模块复用等改变),可以使用Mutations。
Mutations 操作是延迟的:只在存取数据时自动改变,故避免了软件升级时大型数据库转换导致的长时间停机。
复杂的类优化可能涉及到多个类,使用 ConversionStore 进行。因而,无论持久化类作出何种 改变,直接持久层都始终提供可靠数据存取。
Berkeley DB在API的很多地方提供了性能调优的选项。常见的包括:
DatabaseConfig参数
通过DatabaseConfig参数可以用来调整Berkeley DB引擎的性能。
比如,可指定内部B树节点的大小来调整性能,通过如下方式来指定:
1 | DatabaseConfig config = store.getPrimaryConfig(Employer.class); |
CRUD操作参数
例如, “脏读”可通过LockMode参数实现:
Employer employer = employerByName.get(null, "Gizmo Inc", LockMode.READ_UNCOMMITTED);前面提到,交易策略是系统化交易的核心。但是要注意的是,风险管理比交易策略要重要10倍。
交易策略的一些要点整理如下:
所谓规则,规定了一组确定的条件和此条件所产生的结果。根据条件的类别不同,可以把交易策略分成以下几种:
例1
规则定义
评价
简单但完整的交易策略
例2
规则定义
评价
有严重的设计缺陷。因为RSI可能长期不能趋近于某一极值,从而得不到对应的操作信号,长期无法完成完整的买卖周期。
此类策略要研究市场数据的统计分布特征,需要较强的数学功底
例1
规则定义
评价
其思想是捕捉跳空开盘对后市的影响
例2
例3
规则定义
评价
交易周期不完整
这类是最传统、最常见的交易策略
例1
规则定义
评价
简单但完整
例2
规则定义
评价
完整
例3
例4
规则定义
评价
不一定会发生,交易周期不完整
例5
规则定义
评价
不一定会发生,交易周期不完整
需要较强的金融投资理论背景
例1:飞镖系统
规则定义
评价
其收益战胜了华尔街股票分析家,验证了投资学术界的随机行走理论
例2:以满月为买入信号,以新月为卖出信号。
这是一个以金融占星术理论为基础的交易系统。该方法以月球引力场的变化来解释地球生态系统的周期性变比。
例3:硬币法——以随机选择过程为基础
(略)
例: 传言开始是进场,传言证实后出场
基于人工智能、神经网络、混沌理论(Chaos)等
尽管要求交易策略要尽可能简单,但是交易信号产生的条件可能五花八门。为了使交易系统具备更好的适应性,还是应该使用规则引擎来驱动。这就需要将交易策略规则化。
一般来说,交易策略的规则化需要经过确定规则(定性)、确定参数(定量)以及用规则语言描述(实现)三个步骤。
策略定性
将交易策略表示为条件与交易信号。对于最简单的交易策略,可能只有入场信号和出场信号。但也会有一些稍复杂的情况需要处理:
确定参数
将策略中可变的部分定义为参数。这些参数可以在引擎中进行设置,以调整策略的具体行为。
参数可能要经过实际检验,才能得出最优的参数。
定义事件
交易信号都是由某些数据触发,如前所述,这些数据可能是行情、指标、基本面等。
不管是哪种数据,从规则引擎的角度,都需要定义为事件(Event)。
定义操作
规则匹配的结果就是产生某种操作。
考虑到交易策略要与后续的资金管理等策略结合,这里将操作也定义为事件,作为资金管理策略的输入。
描述规则
使用前面定义好的参数、事件和操作,用规则描述语言将定性的策略描述为定量的规则。
以“简单算术平均线”策略为例,其实现过程如下:
规则定性
确定参数
这个策略中,可以作为参数的变量包括:
为简单起见,这里只把均线的长度作为参数。
可以在DRL的global部分用全局变量定义规则的参数。这些参数将用于事件属性或规则条件中,用于调整策略的具体行为。如下:
1 | global java.lang.Integer SHORT_LENGTH; |
global参数可以使用在规则引擎会话中,使用KnowledgeSession的setGlobal()方法进行设置。
事件定义
定义一个“均线事件”(MAEvent):
1 | public class MAEvent { |
并在规则文件中进行声明:
1 | import my.package.MAEvent |
定义操作
这里使用一个“操作信号事件”(SingalEvent)作为操作,符合条件时将该事件insert到规则引擎:
1 | public class SignalEvent extends AbstractEvent{ |
在规则文件中声明:
1 | declare SignalEvent |
描述规则
1 | rule "LONG SIGNAL" |
交易系统离不开行情数据。比如,如果访问新浪的股票数据接口:
http://hq.sinajs.cn/list=sh600133,sh601005
可能会得到如下的数据:
1 | var hq_str_sh600133="东湖高新,6.01,6.01,5.91,6.07,5.80,5.92,5.93,8947052,52872049,2000,5.92,57704,5.91,191500,5.90,75000,5.89,142800,5.88,19700,5.93,43750,5.94,51600,5.95,17299,5.96,11445,5.97,2013-12-18,13:56:49,00"; |
每只股票返回一组数据。以第一组数据为例,各数据项的含义如下:
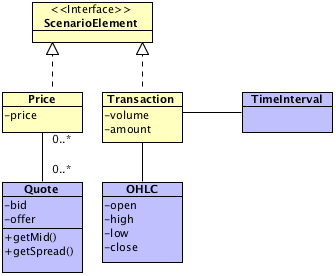
上述的查询结果包含了两种不同的数据:价格(Price)和成交(Transaction)。
价格是实时数据,记录了某一时点的当前价格(price)和一系列(上面的例子中是五组)的报价(Quote)数据;其中报价又包含了买方的出价(bid)和卖方的要价(offer),通常可能表示为“0.6712/5”、“0.2345/”,“/0.4352”等。
成交是阶段数据,记录了某一个时段(上面的例子中是一天)内的开盘价(open),收盘价(close),最高价(high),最低价(low);
以及该段时间内总的成交量(volume)和成交价格(amount)。由于(开盘价,收盘价,最高价,最低价)是很常用的一种结构,比如画蜡烛图时就会使用这种结构,所以将其封装为一个值对象: OHLC 。
不管是价格信息还是成交信息,都关联到某一证券(Security)。
在上面的模型中,价格和成交直接关联到时点。
实际应用中,经常会需要将一些价格或成交聚合在一起。比如,某个市场、某个板块的所有股票的价格。而这种聚合通常要指定到某个时间点才有意义。
可以把这种聚合叫做场景(Scenario),场景关联到某一时间点(TimePoint)。一个场景可以有多个场景元素(ScenarioElement),场景元素作为证券和其他因素之间的关联,聚合到与时点相关的场景中。
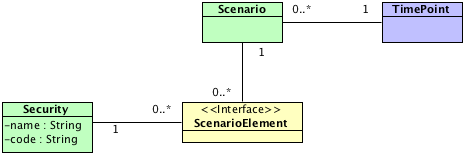
场景提供了一个把所有因素综合在一起的基础,从而可以很方便的在不同的情况之间进行比较。这就有较高的实用性。
比如,在跨市场套利中,可以针对不同的市场定义不同的场景,并将场景关联到指定的市场,从而在不同市场之间进行比较。
在比如在交易系统的风险管理中,可以在多种可能的情况之间进行对比分析。
有了场景和场景元素的定义,则价格和成交都是场景元素的一种实现:
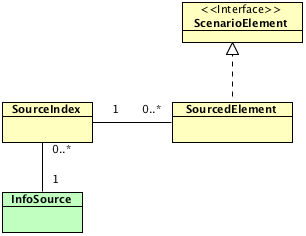
实际应用中,可能需要从多个数据源获取数据。
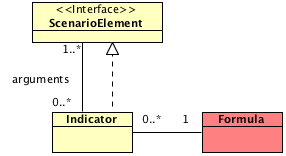
通过其他场景元素计算获取
很多人都从股票投机中赚过钱,但是绝少人能够长期赚钱。甚至这些长期赚钱的人中,绝大部分人的成功次数少于50%。这意味着,证券价格的波动具有随机性。
投资理论界认为,价格的波动具备高度随机性;而投资实务界认为只是部分随机性。
如果价格的波动具备完全随机性,则意味着数据没有任何记忆性,完全无法通过过去的数据预测未来。就好像抛硬币,即使之前抛出了一千次正面,第一千零一次抛出正、反面的概率依然是各占50%。
不可否认,证券价格的变化比抛硬币游戏要复杂得多,目前无法证明其具备完全随机性,但是也无法准确发现其变化规律。
从实践来看,总有人能够从证券投资中稳定获利。尤其近几年一些量化投资方法的成功,又让人看到了通过数学模型获取稳定收益的希望。
尽管人的天性中都厌恶风险(不确定性),但是又都或多或少喜欢赌博。
对于证券投机,可以说本质上也是一种赌博。区别在于大多数人仅仅是赌博,而少数人以数学家的方式参与赌博。
赌博之所以吸引人,在于其概率性。数学家经过思考和技术能够赢得赌博游戏,是因为其对概率和统计学的把握。
要进行科学的投资/投机,而不是以赌博的心态去进行交易,一定要明确以下几点:
投资的目标是持续稳定获利
不要期望每次交易都是正确的,甚至不要期望成功交易的次数要大于失败的次数。据说,华尔街的顶尖交易员在十年中的平均正确率仅仅是35%左右
成功的交易,其收益率不一定高,不要追求单次交易的高回报率——这种事情发生的概率太小
失败的交易,一定要将其损失控制在合理的范围。失败是常态,但是一定不要把一次失败演变成灾难
符合上述行为的投资,就可以称为科学投资,而不是赌博。
科学投资的精髓就是捕捉高度随机变化中的非随机性。
要实现科学投资,需要将一段时间内的所有交易看做一系列整体性、系统化的行为,而不是一次次的“率性而为”。这就要求:
能够做到这些,就可以称之为“系统化交易”。
系统化交易中,最难克服的是心理障碍。请将手放在心口,听我说:
你能否承认交易策略和资金管理策略是指引你交易行为的唯一准则,爱他、安慰他、尊重他、保护他,像你爱自己一样,无论每次交易是成功、是失败,也无论你听到了市场上多么动听的传言,亦或你的交易遭到了何种的嘲讽?
先不要急着回答。人性是如此脆弱,以至于你很快就会释放心中的魔鬼,从而将上面的誓言抛之脑后。请问:
两个选择:1)有75%的机会得到1000美元,但有25%的机会什么都得不到。2)确定可以得到700美元。 你会如何选择?
还是两个选择:1)75%的机会付出1000美元,但有25%的机会什么也不用付出。2)确定付出700美元。 你会如何选择?
可能多数人会在第1个问题中选择2),第二个问题中选择1)。实际上,如果计算了期望值,这两个选择都是错的。这就是你心中的魔鬼。
传言巴菲特有一次打高尔夫的时候球友们跟他打赌:在三天内如果巴菲特打出一次一杆进洞,就给他20000美元,否则巴菲特要付出10美元。但是巴菲特拒绝了。
关住内心的魔鬼,从概率的角度进行思考,绝不要心存侥幸。这才是科学交易的精神。
无论成败,恪守交易策略,才能从大量单个交易的偶然中获取总体期望值的必然;无原则,或者有原则而不遵守,就只能停留在一个个的偶然,并且总体结果也是偶然。
除了心理控制的难关,系统化交易过程中需要进行信息收集、信息处理、交易决策、交易计划、交易执行等大量琐碎耗时的事情,这些事情很可能影响你的心态,甚至由于信息的干扰影响决策的正确性。
此外,系统化交易需要不断对交易策略和资金管理策略不断进行统计分析、优化和参数调整,对于大多数人来说这也是一个难以胜任的工作。
上述种种,需要某种工具来辅助,姑且称之为“交易系统”。
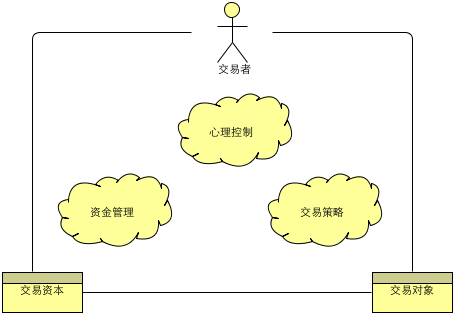
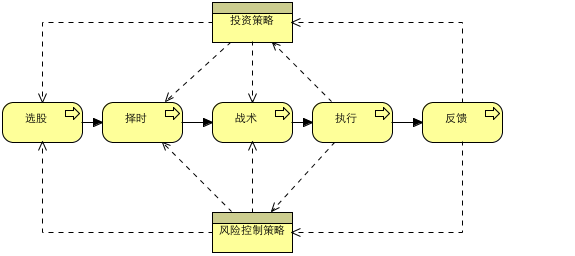
如上图,交易的“铁三角”是交易者、交易资本和交易对象,而交易系统的主要作用是:
交易系统最重要的功能应该是对交易策略的整个生命周期进行管理。
一个交易策略提出后,要经过一系列的阶段,直到最终被废弃。交易策略的生命周期如下图所示:
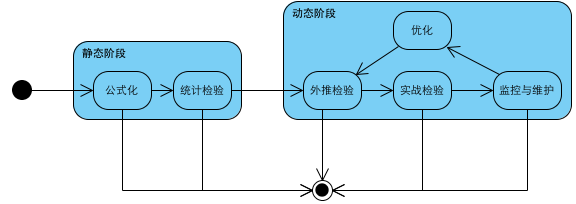
公式化
交易策略中的所有规则,既包括买卖点的生成规则,也包括交易对象筛选的规则等,必须能够用公式/程序语言客观、准确的表示。
并提取出所有的变量/事件和参数。变量/事件用于客观事实的输入,参数用于优化。
当然,对于一些共性的规则,如检查交易对象的流动性和价格波动程度等规则,可以提取出公共的规则,在交易策略中进行引用。
统计检验
使用历史数据对交易策略进行检验,得出交易策略的统计学参数和关键指标
外推检验
使用真实的外部数据,进行模拟盘的操作,检验效果,验证参数和指标的变化
实战检验
使用真实的外部数据,进行实盘操作,检验效果,验证交易策略与交易者之间是否契合
监控与维护
经过上述步骤的交易策略,可以用于实战。在实战过程中要不断监控策略的统计学参数和指标是否已经偏离
优化
在任一环节,如果发现交易策略不能满足要求,可以对参数进行优化
经过验证的交易策略只是给出合适的交易信号:买入信号或卖出信号。根据交易信号、资金状况、策略的统计指标等因素来决定是否要交易、交易量是多少等等这些交易要素,是一个决策的过程。
交易系统应该能够为交易决策提供辅助。
前面提到的交易过程中的其他环节,如信息收集、信息处理、交易日志、结果分析、指标计算等,也需要交易系统进行支持。
同一套交易策略,在不同的交易员手中,效果截然不同。这里面没有对错,而是一个是否适合的问题。
交易策略仅仅规定了交易信号产生的规则,但是不同的交易员具有不同的交易周期长短、风险承受水平、投资理念等偏好,所以会适合不同的交易策略。
所谓最适合的就是最好的,对交易员来说,最重要的时期不是妄图找到“最好”的交易策略,而是应该找到最适合自己投资理念的交易策略。
在符合自己投资理念的前提下,交易过程中要尽量排除不必要的主观性。对于每对交易,不要关注是成功还是失败,而要关注是对的还是错的:
尽管我们希望在有限的条件下建立一个科学的模型,从而获得一个正的“预期收益率”(该死的银行理财产品?),但是,我们还是将命运交给了未知:那冥冥中的概率。
尽管根据大数定律,随着交易次数的增多,总体结果会越来越接近事先计算出的期望值,但是中心极限定理指出,大量独立随机变量的平均数近似正态分布。
就我们有限而短暂的生命来说,我们不可能让交易次数达到无穷,去逼近那个理论中的“期望值“,而只能进行有限次数的交易。如果说一套交易策略,由不同的交易者去实践,则每个交易者的最终结果可以看做中心极限定理中的一个样本。
很遗憾,中心极限定理告诉我们,最终结果是近似正态分布的,也就是说:有限次的策略交易,最终的统计结果仍然是一个概率分布——正所谓谋事在人,成事在天。
统计学:从数据到结论,ISBN:9787503749964,作者:吴喜之 @豆瓣
对于一个模型,需要调整其各个因子(factor),以使模型达到最好的效果。
每个因子的取值是离散的,称为该因子的水平(level)
需要对各个因子的不同水平进行组合实验,才能得出一组最佳的因子水平
如何设置因子的不同水平,以及如何进行组合实验,属于实验设计的范畴,实验设计模型可以说是回归模型的一种。
这里探讨的不是如何设计实验,而是如何对实验的结果进行分析
方差分析(analysis of variance, ANOVA),分析各个自变量对因变量的影响的一种方法。
自变量包括:
分析的结果是一个方差分析表
原理:
对因变量的影响包括各个因素的主效应(main effect)、交互效应(interaction)和协变量
对于两个自变量(水平分别为3个和4个)的一个模型,如果只考虑主效应,其线性模型为:
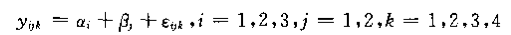
其中:
此时的线性模型增加了交叉项:
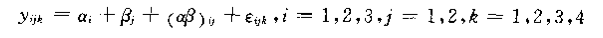
此时的模型变成:
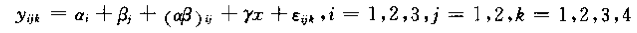
加上了一个自变量x,及其相关系数。
统计学:从数据到结论,ISBN:9787503749964,作者:吴喜之 @豆瓣
列连表研究2个或以上的变量,每个变量的取值是离散的,取值的总数量称为该变量的“水平”。
列连表记录这些变量的各种取值组合出现的次数,以研究这些变量之间的相关性。
比如:

上图记录了一个3x2x2的列连表,三个变量分别为收入(高、中、低)、观点(同意、反对)、性别(男,女)。
软件处理时通常将列连表处理成二维表格,比如:

比如以下的二维列连表:

设定零假设和备选假设:
H0:观点和收入不相关<=>H1:相关
检验逻辑:
检验统计量在零假设下有(大样本时)近似的x2分布。
当该统计量很大时或p-值很小时,就可以拒绝零假设,认为两个变量相关。
x2检验量还可以使用Pearson x^2统计量和似然比(likelihood ratio) x2 统计量
(公式:略)
高维列联表的检验和两维类似
但高维列联表可以构造一个(多项分布)对数线性模型(loglinear model)来进行分析。
好处:不仅可以直接进行预测,而且可以增加定量变量作为模型自变量的一部分。
ln(mij)= ai + bj + eij
其中:
ln(mij)= ai + bj + (ab)ij + eij
增加了交叉效应(ab)ij,代表第一个变量的第i个水平和第二个变量的第j个水平对ln(mij)的共同影响
很多事件符合Poisson分布,需要使用 Poisson对数线性模型进行分析。
ln(l) = u + ai + bj + gx
其中:
……
统计学:从数据到结论,ISBN:9787503749964,作者:吴喜之 @豆瓣
统计实践的最终目的:发现变量之间的统计关系并帮助决策
变量关系的模型:Y=f(x)
则:
回归模型的作用:
注意:自变量和因变量不一定有因果关系
确定两个定量变量是否有关系:最简单的办法是散点图
对于相关程度的度量:
将相关模型表示为分段函数
适合因变量为定性变量的相关性分析
统计学:从数据到结论,ISBN:9787503749964,作者:吴喜之 @豆瓣
证明一件事情比较难,证伪一件事情比较容易
科学研究的一个基本方法就是假设检验:
统计学中的假设检验方法也是一样,只不过关注点是统计量之间关系的假设
注意:假设不能被推翻,也仅仅是假设。因为无法证明其能覆盖所有的情况。对于统计学领域尤其如此
比如检查商品的份量是否充足:进行抽样后检验。单个商品的称量结果有多有少,
如何判断总体的份量是否足够?仅用样本的平价重量进行评价是不科学的!
H0H1H0:u>=u0 <=> H1:u<u0 。其中<=>相当于“versus”该逻辑中,H0和H1的地位不对称:按照H0推导分布,只要不符合就可以推翻H0
上面的逻辑并不严谨:
小概率事件也有可能真实发生!
所以统计结论也有可能犯错误。两种错误情况:
第一类错误(type I error): 按照H0假设,样本数据为小概率事件,于是拒绝H0。但总体的真实情况是符合H0
第二类错误(type II error):按照H0假设,样本数据的概率很大,于是接受H0。但总体的真实情况是不符合H0
(略)
结论:不能说“接受零假设”,更严谨的说法是“不拒绝零假设”